
When was the last time your project ended smoothly — without delays, surprises, or last-minute compromises? In reality, most UX projects go off course as timelines slip, budgets stretch, and features change. How can we better navigate the chaos? An upcoming part of our series “How to Measure UX and Design Impact.”
BLOG POST: Think about your past projects. Were they completed on time and within budget? Were they implemented without compromises? Were they disrupted along the way by scope changes, competing interests, unexpected delays, and surprising blockers?
Chances are, your recent project exceeded its timeline and budget — just like the vast majority of other complex UX projects. Especially if it involved any kind of complexity, whether a large stakeholder group, a specialized domain, internal software, or expert users. It may have been delayed, moved, canceled, “refined,” or postponed until later. It turns out that, in many teams, on-time delivery is the exception, not the rule.
In truth, things almost never go according to plan — and in complex projects, they rarely even come close. So how can we prevent that? Well, let’s find out.

99.5% of large projects exceed budgets and timelines
As humans, we are naturally too optimistic and too confident. It is difficult to study and process everything that can go wrong, so we tend to focus on the bright side. But unchecked optimism leads to unrealistic forecasts, poorly defined goals, ignored better alternatives, overlooked problems, and no contingency plans for inevitable surprises.

Hofstadter’s Law states that the time required to complete a project will always expand to fill all the available time — even when you take Hofstadter’s Law into account. In other words, it always takes longer than you expect, no matter how careful you are.
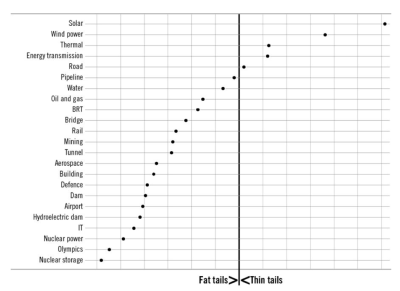
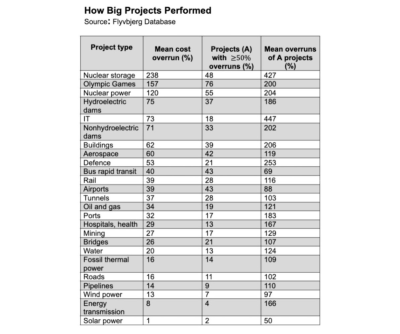
As a result, only 0.5% of large projects stay within budget and timelines — for example, major upgrades, legacy system rebuilds, and large initiatives. We can try to soften the risk by adding a 15–20% buffer — but that rarely helps. Many of these projects do not follow a “normal” bell-curve distribution, but a fat-tailed distribution.
And there, overruns of 60–500% are typical, turning large projects into huge disasters.
Reference-class forecasting (RCF)
We often assume that if we simply collect all the relevant costs and estimate complexity or effort carefully, we should end up with a decent estimate of where we will land. Nothing could be further from the truth.
Complex projects have many unknown unknowns. No matter how many risks, dependencies, and upfront challenges we identify, there are many more that we cannot even imagine. The best way to be more accurate is to establish a realistic anchor — for time, cost, and benefit — based on similar projects completed in the past.
Reference-class forecasting follows a very simple process:
- First, we find reference projects that have the most similarities to our project.
- If the distribution follows a bell curve, we use the average value + 10–15% for contingencies.
- If the distribution is fat-tailed, we invest in deep risk management to avoid major future challenges.
- We adjust the average value only if we have very good reasons to do so.
- Create a database to track past projects in your company by cost, time, and benefit.
Mapping user success moments
For the past few years, we have been using a method called “Event Storming,” proposed many years ago by Matteo Cavucci. The idea is to capture user experience moments through the lens of business needs. When applying it, we focus on the desired business outcome, then use research insights to design the events users will experience while moving toward that outcome.

The image above shows the process in action — with different lanes representing different points of interest, and prioritized user events grouped into themes, together with risks, obstacles, stakeholders, and users to involve — as well as UX metrics. From here, we can identify shared themes that emerge and build a common understanding of risks, constraints, and the people who need to be involved.
Throughout this journey, we identify key stages and divide user events into two main groups:
- User success moments that we want to strengthen ↑;
- User pain points or frustrations that we want to reduce ↓.
Then we split into groups of 3–4 people to prioritize these events separately and evaluate their impact and effort using John Cutler’s effort/value curves.

The next step is to identify the key stakeholders to communicate with, the risks to consider, such as legacy systems or third-party dependencies, and the resources and tools required. We dedicate specific time to identifying the main blockers and constraints that threaten a successful outcome or slow us down. If possible, we also define UX metrics so we can track how successfully we are improving the current state of the user experience.
This may feel like too much planning for a UX project, but it has significantly helped reduce failures and delays while maximizing business impact.
When speaking with the business, we usually talk about better discovery and scoping as the best way to reduce risk. Of course, we can throw ideas into the market and run endless experiments. But not for critical, high-visibility projects, such as replacing legacy systems or launching a new product. These require careful planning to avoid major disasters, emergency rollbacks, and… black swans.
Managing the “black swan”
Every other project encounters what is known as a “black swan” — a low-probability, high-impact event that becomes more likely when projects run for a long time. This can be anything from team restructuring to changing priorities, which then leads to cancellations and replanning.
Small problems have an incredible ability to accumulate into large, catastrophic problems — derailing big projects and sinking big ambitions at a phenomenal scale. The more small problems we can solve early, the better chance we have of successfully delivering the project.
So, we make projects smaller and shorter. We reduce risk by involving stakeholders early. We give less space for “black swans” to appear. A good way to achieve this is to always start every project with a simple question: “Why are we actually doing this project?” The answers often reveal not only motivations and ambitions, but also challenges and dependencies hidden between the lines of the task.
And when planning, we can follow “right-to-left thinking.” We do not start from where we are, but from where we want to be. Then, when planning and designing, we move from the future state back toward the current state, exploring what is missing or what prevents us from getting there. The trick is this: we always keep our final goal in mind, and our decisions and milestones are always shaped by that goal.
Manage the experience deficit
Complex projects begin with a large experience deficit. To increase the likelihood of success, we need to reduce the opportunity for mistakes to appear. That means trying to make the process as repeatable as possible — with smaller “work modules” that teams repeat again and again.

🚫 Beware of unchecked optimism → unrealistic forecasts.
🚫 Beware of “cutting-edge” → untested technology increases risk.
🚫 Beware of “unique” → high likelihood that costs will explode.
🚫 Beware of “entirely new” → rely on what has been tested and proven.
🚫 Beware of “largest” → build small things, then connect them.
This also means relying on trusted elements: from well-tested tools to stable teams that have worked well together in the past. Complex projects are not a good place to innovate on processes, reshuffle teams, or test cheaper vendors.
These are usually hidden extreme costs that greatly increase delivery delays and unexpected expenses.
Think slowly, act quickly
As deadlines approach, many projects rush into implementation mode before the project scope is well defined. This can work for quick experiments and small changes, but it is a warning sign for larger projects. The best strategy is to spend more time on planning before drawing even a single pixel on the screen.
But planning is not abstract imagination work. Good planning should include experiments, tests, simulations, and refinements. It must include steps for how we reduce risks and how we mitigate risks when something unexpected, but common in similar projects, happens.
Good design is good risk management
When speaking about design and research with senior leadership, present it as a powerful risk management tool. Good design, which includes concept testing, experimentation, user feedback, iterations, and plan refinement, is cheap and safe.
In the end, it may take longer than expected, but it is much — MUCH! — cheaper than implementation. Implementation is extremely expensive, and if it is based on wrong assumptions and poor planning, the project becomes vulnerable and difficult to change or redirect.
Wrapping up
The insights above come from the excellent book “How Big Things Get Done” by Prof. Bent Flyvbjerg and Dan Gardner. It describes in detail how large projects fail and when they succeed. It is not a book about design, but it is a fantastic book for designers who want to plan and estimate better.
Not every team will work on a large, complex project, but sometimes these projects become unavoidable — when working with legacy systems, high-visibility initiatives, layers of politics, or an entirely new domain the company is moving into.
Successful projects have one thing in common: they spend most of their time planning and managing risks and unknown unknowns. They avoid sudden big discoveries and instead test continuously and repeatedly. This is your best chance of success — to work around these unknowns, because you will not be able to fully prevent them from appearing anyway.


.webp)
.webp)
.webp)
.webp)
.webp)